
Like many other medievalists, this past weekend I attended the International Congress on Medieval Studies at Western Michigan University in Kalamazoo. While there, I was privileged to present on a special session titled “Source Study: A Retrospective,” sponsored by the Sources of Anglo-Saxon Culture (my thanks to Ben Weber for organizing and for including me). I was also grateful for the questions and discussion in the Q&A as well as after the session, so thanks to those who attended. Below is the content of my talk. I’m posting it here in the same spirit with which I presented it: in the hopes that it will be received as a call for other collaborators in the work I love and hope to continue—not only source study as it has been traditionally defined, but as we might continually reimagine, remake, and extend it in our scholarship.
In the “Foreword” to Sources of Anglo-Saxon Literary Culture, Volume One, in 2001, Paul Szarmach (then the Project Director) gave an institutional history of the project, as well as some thoughts about its future directions.[1] He provide some prescient comments about the future of source study in light of computers:
The computer, its pomps, and its works have made much possible and easy, while requiring and demanding other responses such as apparent continual retraining, reconfiguring data for new software, and reinfusion of financial support to keep up with the cunning churn of new equipment….[2]
Over the intervening fourteen years, the Sources of Anglo-Saxon Literary Culture (SASLC) project in particular and source study in general have continued, and computers have, of course, remained increasingly significant in this work. The point here is not to provide another institutional history, but some of the ways in which our so-called “digital age” opens up fresh possibilities for moving source study ahead, for asking new questions, or old questions in light of new developments, and for exploring new avenues for our methods.
This paper is not meant to be a procedural guide to source study. Some already exist, such as various SASLC guides, as well as Rebecca Shores’s recent, provocative blog post, “Ælfric and the Rabbit Hole,” with her discussion of dealing with the many outstanding problems in Ælfrician source study. Nor is this a workshop to introduce the myriad digital tools that might be employed for source study—although there are many, and promising developments in that area regularly emerge. Instead, this paper is a reflection on possibilities that I’m exploring in my own work, with an invitation for others to join me in these pursuits. I want to start with some methodological reflections, move through some critiques, and finish with some practical examples.
While the title of my talk is “Source Study in a Digital Age,” what I’m really interested in is something that I’ve been thinking about more broadly as “transmission studies.” This perspective encompasses manuscript evidence, sources, translations, allusions, intertextualities, and adaptations—not only textual but across different media artifacts. While these topics are necessarily related, each presents a distinct issue, and no one methodology covers all of them. After all, bibliography, source studies, translation studies, and adaptation studies are often undertaken as separate fields of inquiry. How, then, do we pull them all together? In what follows, I suggest that we may do so not only with digital tools but also with methodological frameworks that have emerged from studying digital media.
Recently, space for theorizing the past has opened up due to studies in media archaeology, engaged in excavating artifacts of the past as part of the layers of media leading up to the present.[4] In this light, the medieval world provides an abundance of possibilities for exploring premodern multimedia culture. Yet there has been little sustained critique of medieval artifacts as media specifically and directly, with only a handful of recent examples of this type of work.[5] Kathleen Kennedy has critiqued the tendency toward presentism in studies of so-called “new media,” calling for the use of media archaeology to examine the long history of media stretching back into premodern periods; as she says, “Media and the cultures that produce it today rest high atop substrata that may look quite different from the surface, yet the older still influences the newer.”[6] Under the banner of “Old Media Studies,” it is the responsibility of scholars of premodern media to excavate these layers. From this perspective, in some ways, a subtitle for my talk might be offered as “A Prolegomenon for Transmission Studies through Media Archaeology.” Through this lens, I want to think about one way in which media archaeology can help us think about medieval culture—that is, the “big data” we have inherited from Anglo-Saxons, and how we approach such massive amounts of data. Through a media archaeology lens, thinking about the longue durée of media also allows us to think about the ways in which big data stretches across time, and how we deal with the data of the past in our current research.
By “big data,” I mean the sheer amount of material that we have inherited, particularly from Anglo-Saxon England. According to the Dictionary of Old English website, the “Web Corpus represents over three million words of Old English”—as well as several hundred thousand words of Latin—making up “almost five times the collected works of Shakespeare.”[7] The Latin included, however, is only a small amount, and no comparable Anglo-Latin corpus exists. To give some more numbers, as of 2014, the Brepols Library of Latin Texts series A includes over 74.1 million word-forms, from 3,625 works; series B includes almost 24.7 million word-forms, from 723 works. The Perseus Digital Library contains 10,525,338 words in Latin, and the collection is ever growing. While not all of these works are relevant to Anglo-Saxonists—since they’re from a later period—many of them represent sources or contemporary analogues to explore. Even individual texts (from a range of medieval cultures) pose large amounts of data, as on the slide.[8]
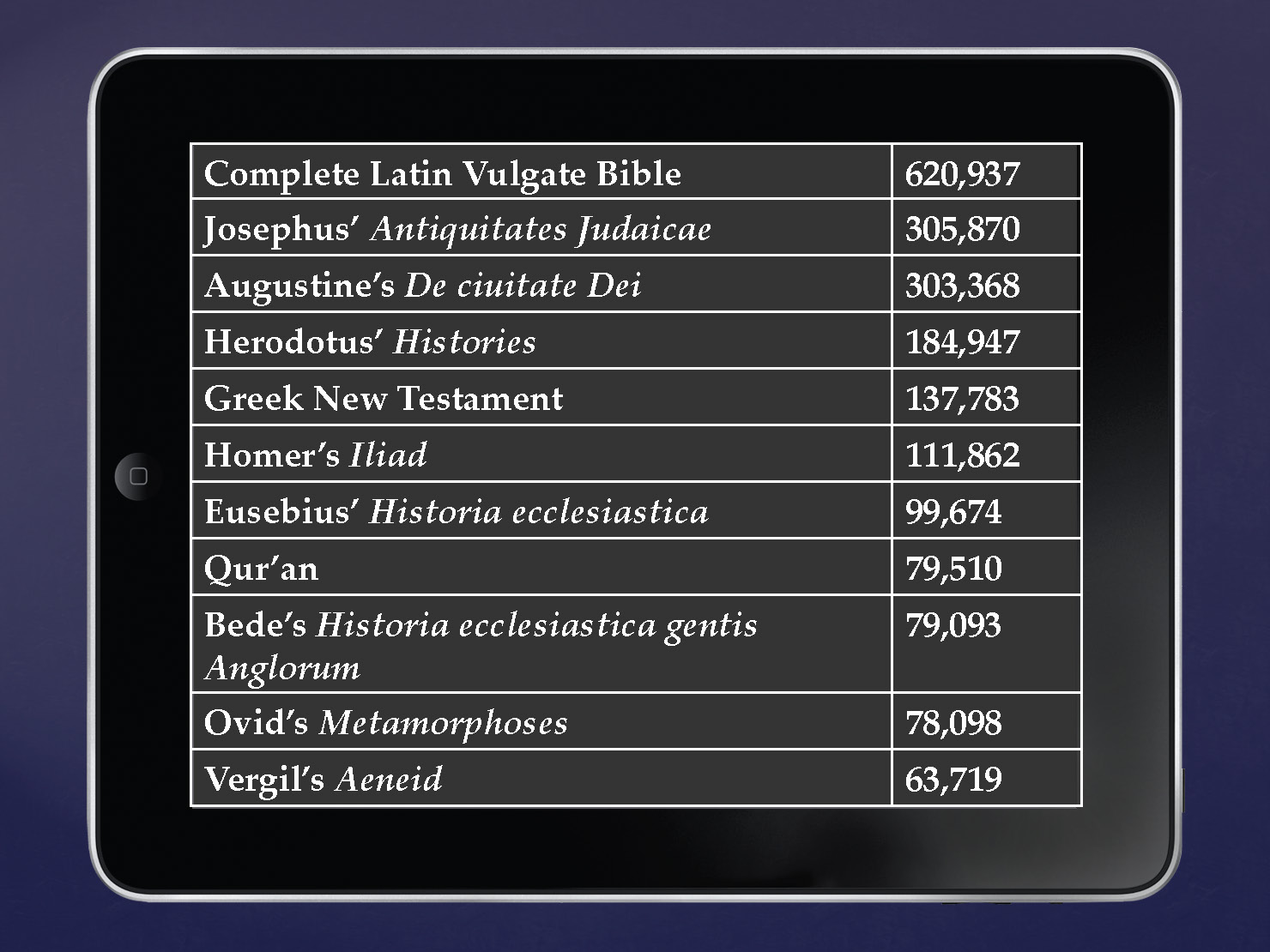
This is big data indeed.
Literary scholars in other fields have found useful ways to wrangle big data from their own periods. This way of viewing texts has been fruitfully used for text mining with digital tools, which Franco Moretti calls “distant reading” and Matthew L. Jockers calls “macroanalysis”—using computers to analyze large corpora of literature for relationships between texts.[9] Much of this has been facilitated by the digitization of and open access to works in the public domain, like eighteenth- and nineteenth-century novels.
All of this poses three interrelated issues that I want to address today: first, the massive amount of Anglo-Saxon textual data that we need to work with; second, the accessibility of this corpus; and, third, what we can do with this data using digital tools. To do so, I will both make general remarks and point to specific examples as they are helpful. My examples are necessarily selective, and many of them come from my own work. But the implications may be extrapolated to myriad other applications for our research.
First, the big data of Anglo-Saxon literary culture. I’ve already mentioned some of the corpora that we have to reckon with in our work, but even those resources represent only the tip of the massive iceberg of textual data that still sits in archives. As the recent catalogue of Anglo-Saxon Manuscripts by Helmut Gneuss and Michael Lapidge attests, there are 1,291 “manuscripts and manuscript fragments written or owned in England up to 1100.” This does not include single-leaf documents, manuscripts written by or accessible to Anglo-Saxons on the Continent, nor the many Anglo-Saxon-related manuscripts and texts that were copied later, well into the thirteenth century. Many of these manuscripts remain untranscribed, unedited, and inaccessible even in digital facsimiles. While the Dictionary of Old English boasts a large corpus of texts, theirs are curated versions, often based on critical editions that conflate readings from individual texts. What of other versions? I suggest—and I’m not the first—that we should consider each iteration of a work, in every manuscript, as a text in its own right. But how do we deal with that amount of big data?
A few thoughts on that issue. Recently, I have been experimenting with Optical Character Recognition (or OCR), with the hope that perhaps digital tools can help us to read and transcribe texts from manuscripts into computer-readable forms. While this type of work has been a boon to those who work with the digitized media available from projects like Google Books, there has been less exploration of OCR for non-printed media. Another possibility is in crowd-sourced transcription. Again, scholars in other periods have found useful ways of harnessing collaborative teams, as with the large task of the Transcribe Bentham project. Perhaps more Anglo-Saxonists turning toward group transcriptions of manuscripts could lead to greater access to the big data that we rely on for literary study in our field. I have begun some of this work with my own Judith project, in which I have transcribed and put online every source accessible to Anglo-Saxons that mentions or engages with the biblical book and figure of Judith (see the Omeka archive [moving soon] and the project blog). These include texts from patristic and early medieval authors, in Latin and Old English, comprising a corpus of fifty works. Yet this is a just a small amount of the larger pool of big data that could be made more accessible.
This leads to my second point: accessibility. I’ve already mentioned some of the major resources for our work as source and literary scholars: like the Dictionary of Old English, the Patrologia Latina, and the Brepols Library of Latin Texts. But we need these to be open and free, not hidden behind paywalls and corporate subscriptions.
Many libraries are already taking the lead in this respect, with thousands of medieval manuscripts now available online for free. In just the past few weeks, the University of Pennsylvania has launched their OPenn project, following in the footsteps of institutions like the Walters Art Museum and the Swiss e-codices initiative. But these are only manuscripts. What about texts in useable forms? We are still reliant on cost-prohibitive subscriptions to access some of our most valuable resources, like the Dictionary of Old English, the Chadwyck-Healey Patrologia Latina database, and the Brepols Library of Latin Texts. Fortunately, projects like the Perseus Library and the Monumenta Latin texts archive are continually growing with free, open access to texts that rest as the basis of source study. Without free, open texts, the use of digital tools to study them is a moot point. We need to develop new textual databases, under licenses like Creative Commons, which allow scholars to use them for innovative pursuits. Of course, there are complicated issues to consider with pleading for free and open resources—including who gets paid, and how, for academic work and publications, how open access works, etc. So instead of harping on, I’ll move on, to discuss what we can do with big data once we have access to it.
In some ways, the results of using digital tools often speak for themselves. Yet, in other ways, these explorations are just in their infancy. Macroanalysis, or distant reading, of big data is becoming more and more an accessible way of analyzing texts with computers as new tools emerge, and such examinations are becoming more sophisticated over time. No longer are scholars just counting word frequencies; we are now starting to conceptualize how word clusters move together, how style can be analyzed from linguistic markers, and how large corpora can reveal trends across texts by a single author or multiple authors.
To give one example of possibilities for source study, I’ll point toward new avenues in classics, exploring Greek and Latin literature with digital tools. Like medievalists, classicists have regarded source study as a foundational staple of their research, using it as the basis of productive theoretical discussions of literary influence and intertextuality. One promising digital humanities project, for example, is Tesserae, a collaborative project led by Neil Coffee, in Classics at SUNY Buffalo, and J.-P. Koenig, in Linguistics at SUNY Buffalo. The Tesserae project has so far created an online interface for studying intertextual parallels across Greek and Latin texts. For example, users are able to select Horace as source author and Jerome as target author, creating an output that shows a list containing: parallel phrases across their texts (based on a minimum of two words across the texts); verbal parallels that determine the matches; and a score (on a scale from zero to ten) representing the intertextual proximity of the source and target text—with rarer words and proximity in the texts determining higher scores.[10] Although the focus is on classical Greek and Latin literature, the project encompasses the entire Perseus Latin corpus (including some medieval texts, such as Bede and Paul the Deacon) plus many Greek and English texts, with further goals of expanding in the future. It’s easy to see the possibilities for source study, if these tools can be harnessed for Anglo-Latin and Old English texts.
Finally, I’ll conclude with just a few aspects my own research exploring the transmission and influence of Judith in Anglo-Saxon England. As I stated before, this work is based on a corpus of 50 texts, including patristic and early medieval Latin, and Old English literature. All of these revolve around the single biblical source of the book of Judith. This project, then, contributes to what more we can say about the text and influence of biblical material in Anglo-Saxon England. But digital tools also show some compelling ways for thinking about the media networks between the Anglo-Saxon materials.
Creating a corpus was the first major step, since it meant compiling known sources and known Anglo-Saxon texts—and evidence for how these were known, in manuscripts, citations, quotations, et cetera. In the case of Hrabanus Maurus’ commentary on Judith, it meant returning to the single surviving manuscript that we know circulated in England before 1200, in order to create a single-text edition (here’s a draft, as pdf, but this is still under development) that represents the version Anglo-Saxons could have read rather than a critical edition. This corpus, once created, could then be published and analyzed using digital tools. Distant reading (see this post) revealed basics like most frequent words in these texts; these were, unsurprisingly, mainly characters and religious terms. But they also revealed how certain word phrases—linguistic collocates, or collocate clusters—appear together in the texts, showing conceptual connections. These are just some simple examples to show how text mining, or distant reading, can reveal interconnections, but they point toward the possibilities of more work like this.
Another aspect worth mentioning is the ability to think about the circulation of manuscripts mapped out geographically. What can we determine about the manuscripts containing texts in this Judith corpus? Where were they held, at what points, and who might have had access to them? Here is one map that shows the provenances; and here are some more experiments in mapping; I hope that, with further work and collaboration, I can place these points not only geographically but also temporally. The motivating question is, If an author were in Canterbury in the year 950, what texts about Judith would he have access to in the local libraries? The implications could go much further, however, if we began to map out every manuscript known to the Anglo-Saxons, to understand libraries and book transmission. But this is not the work of one; this is the work of many collaborators working together.
But the SASLC project is changing, developing a new publishing model in which print publication of entries will be accompanied by an online platform. This Digital Research Center (as we’re calling it) will include publication of entries and resources as well as a space for scholars to work together. Finally, this all leads to one more set of thoughts: Why not use the emerging SASLC Digital Research Center as a meeting-place for the types of work I’ve discussed? In this sense, we might imagine this online endeavor as a repository for corpora of big data, a virtual space for scholars to work on mining the archives and publishing source-related discoveries, and a community for sharing research like entries for SASLC as well as new modes of examination and publication. For all of this, we need the collaboration of financial and research support from a variety of institutions and individual scholars; with a network of cross-institutional support, the Research Center can be all the more robust and central to future research. If we dare to imagine such a collaborative space, we might be able to host resources for source study as it already exists and as we forge ahead into our digital age.
Notes
[1] Paul E. Szarmach, “Foreword,” Sources of Anglo-Saxon Literary Culture, Volume One: Abbo of Fleury, Abbo of Saint-Germain-des-Prés, and Acta Sanctorum, ed. Frederick M. Biggs et al. (Kalamazoo, MI: Medieval Institute Publications, 2001), vii-xiv.
[2] Ibid., viii.
[3] “Ælfric and the Rabbit Hole,” Suburban Academic: Musings of a Domesticated Scholar, February 6, 2015, http://suburbanacademic.com/2015/02/aelfric-rabbit-hole.html.
[4] See Media Archaeology: Approaches, Applications, and Implications, ed. Erkki Huhtamo and Jussi Parikka (Berkeley, 2011); Jussi Parikka, What Is Media Archaeology? (Cambridge, 2012); and Michael Goddard, “Opening up the Black Boxes: Media Archaeology, ‘Anarchaeology’ and Media Materiality,” New Media & Society (2014), 1-16.
[5] See Martin K. Foys, Virtually Anglo-Saxon: Old Media, New Media, and Early Medieval Studies in the Late Age of Print (Gainesville, FL, 2007); idem, “Media,” A Handbook of Anglo-Saxon Studies, ed. Jacqueline Stodnick and Renée R. Trilling (Malden, MA, 2012), 133-48; Kathleen E. Kennedy, Medieval Hackers (Brooklyn, 2014); and Fiona Somerset, “Introduction,” Truth and Tales: Cultural Mobility and Medieval Media, ed. Fiona Somerset and Nicholas Watson (Columbus, 2015), 1-16.
[6] In a recent talk for the University of Virginia, “Old Media Studies: New Wine from Old Skins,” The Absurd Box, November 17, 2014, http://drredneck.tumblr.com/post/102885823332/old-media-studies-in-motion, accessed January 2015; also see her Medieval Hackers.
[7] http://doe.utoronto.ca/pages/pub/web-corpus.html.
[8] Josephus’ Antiquitates Judaicae 305,870; Augustine’s De ciuitate Dei 303,368;[8] Herodotus’ Histories 184,947; the Greek New Testament 137,783; Josephus’ De bello Judaico 125,221; Homer’s Iliad 111,862; Eusebius’ Historia ecclesiastica 99,674; Homer’s Odyssey 87,185; the Qur’an 79,510; Bede’s Historia ecclesiastica gentis Anglorum 79,093; Ovid’s Metamorphoses 78,098; Vergil’s Aeneid 63,719; Juvenal’s Saturae, 26,564; and Horace’s Carmina 13,292.
[9] Franco Moretti, Distant Reading (London, 2012); and Matthew L. Jockers, Macroanalysis: Digital Methods and Literary History (Urbana, IL, 2013).
[10] This particular search between texts by Horace and Jerome provides 9672 results, ranging from scores of 0 (only 1 instance) to 10 (2 instances). The methodology behind the software is discussed in various posts on the project blog, at http://tesserae.caset.buffalo.edu/blog/.

One thought on “Source Study in a Digital Age”